由于内容偏多,我将《基于回归算法预测股市价格》实验项目拆分成了多篇文章。这是该系列的第 一 篇文章!这里主要介绍数据的基本情况、数据预处理等内容。
相关文章链接:
- 第一篇:基于回归算法预测股市价格(Part 1)(正在阅读)
- 第二篇:基于回归算法预测股市价格(Part 2)
- 第三篇:基于回归算法预测股市价格(Part 3: Estimating with Linear Regression)
- 第四篇:基于回归算法预测股市价格(Part 4: Estimating with Tree-based Regression)
- 第五篇:基于回归算法预测股市价格(Part 5: Estimating with Network-based Regression)
本项目的目标是展示如何使用不同的回归算法进行股票价格预测。这里将从传统方法,如线性回归、回归树开始,一直到更复杂的机器学习和深度学习方法,如随机森林(Random Forest)、支持向量回归(Support Vector Regression,SVR)、长短期记忆网络(Long Short-Term Memory Network,LSTM)、卷积神经网络(Convolutional Neural Network,CNN)以及自回归长短期记忆网络(Autoregressive Long Short-Term Memory Network,ARLSTM)。通过这个项目,共同学习如何用 Python 进行数据预处理、模型训练和评估,并探索不同算法在股票价格预测中的表现,从而加深对回归算法及其在商务智能领域应用的理解。
Data Source
项目使用的数据集来源于 Kaggle:Stock Market Data。请自行下载。
这里将使用纽约证券交易所(NYSE)IBM 股票的数据集作为样本,该数据集包含七个关键特征,具体如下:
- Date(日期)
- Volume(成交量):指在该时间段内交易的股票总数。
- High(最高价):该股票在指定时间段内的最高交易价格。
- Low(最低价):该股票在指定时间段内的最低交易价格。
- Open(开盘价):该股票在市场开盘时的交易价格。
- Close(收盘价):指当日交易结束时的股票价格,即市场关闭前交易者达成的最后成交价格。
- Adjusted Close(调整收盘价):相比于简单的收盘价,调整收盘价考虑了股息、股票拆分以及新股发行等因素的影响,因此更能反映股票的实际价值。
显然,我们的主要预测目标是收盘价(Closing Price),因为它代表了股票在正常交易时段内的最终成交价格,是投资者进行技术分析和决策的重要指标。
What Is Regression?
Regression Stage
Example of Linear Regression
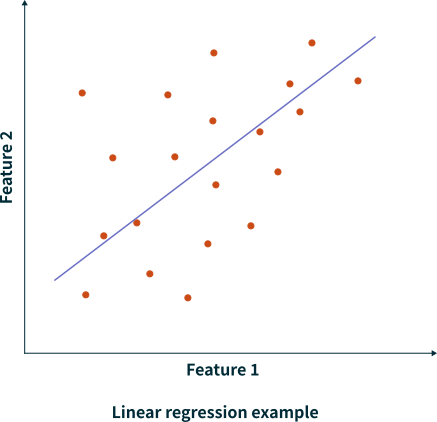
Workflow of Trainning Regression Model
机器学习大致遵循如下图所示的流程。首先,我们需要收集原始数据,并将其划分为训练集(train set)和测试集(test set),以确保最终模型评估的客观性。在数据量充足的情况下,训练集可进一步二次划分为训练子集(sub-training set)和验证集(validation set),用于超参数调优。随后,我们在训练数据上进行特征工程,包括缺失值填充、标准化、特征构建等。特征工程中的所有统计计算(如均值、标准差等)仅使用训练数据,并需严格保证测试数据的未见(hold-out)性,以防止数据泄露(Data Leakage),从而模拟真实环境。如果涉及与数据分布无关的特征处理(如提取文本长度、日期信息等),则可以在数据划分前执行。在训练过程中,我们使用训练子集训练模型,并利用验证集调整超参数,以优化模型性能。对于数据较少的情况,可以使用交叉验证(Cross-validation),K 折(K-fold)交叉验证,来代替单次划分,以提高模型的泛化能力。完成训练后,最终使用测试集进行评估,确保模型在真实环境中的表现。测试集在整个过程中始终不参与训练或超参数调整,以保持评估结果的可信度。此外,为了防止数据泄露、优化特征工程与训练流程,我们可以使用 Pipeline 进行端到端的自动化处理,确保整个流程的规范性和可复现性。
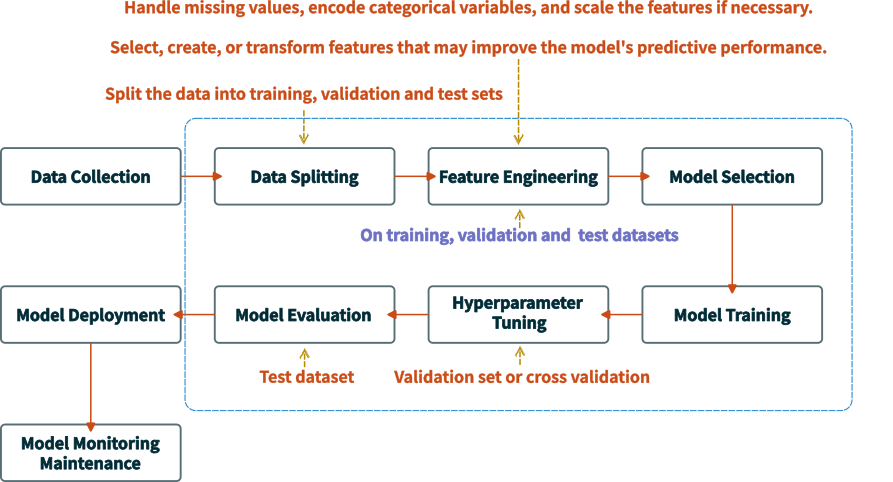
需要注意的是,这里将数据划分提到了特征工程前,其目的主要是为了尽可能地避免数据泄露问题。如果将其放在特征工程后,那么在对数据进行预处理(如标准化、缺失值填充)或者特征工程(如 mean, std 等基于全量数据的特征构建)时会使用测试集信息。这会导致模型在训练阶段已间接"看到"测试集数据,从而使得验证指标虚高,无法反映真实泛化能力。当然,如前文所述,对于那些与数据分布无关的特征处理(如:提取文本长度、提取日期中的星期几),也可先处理再进行划分。
🤓 Note
数据泄漏指的是在构建或训练机器学习模型时,模型不恰当地使用了在真实预测场景下不可用的信息,从而导致对模型性能的过度乐观估计。换句话说,模型在训练阶段获得了“未来”或“预测时不可用”的数据,这些信息在真实应用中并不能被提前获取。可以通过如下方式尽可能的避免数据泄露:1)严格划分训练集、验证集、测试集:在做任何预处理或特征工程之前,就要先划分数据集,保证测试集在整个建模过程中是完全隔离的;2)基于时序的数据处理:对时间序列预测时,应严格遵守时间先后顺序,只能使用在预测时点之前已经产生或可获取的数据来训练模型;3)仔细审查特征与目标的关系:在特征工程阶段,仔细检查特征是否包含了与目标变量强相关甚至重复的信息,若有则需剔除或修正;4)保持与真实业务场景的一致性:设计模型时要考虑实际应用中的数据获取时点,确保在模型做出预测的那一刻,这些特征信息在现实中确实是可以被获取到的。
Data wrangling and preprocessing
Loading Raw Data
首先,我们需要将数据加载到工作空间中
import pandas as pd
_train_data = pd.read_csv(train_data_path)
🤓 Note
从 Stock Market Data 下载的数据集包括
csv和json两种格式,同一公司的不同格式的数据集似乎一致。这里使用pandas库提供的read_csv方法读取对应的csv格式数据。如果需要读取json格式,可以使用pandas库提供的read_json。这两种方法均将对应的数据转换为相应的pandas对象(object),比如DataFrame.
Checking Basic Infomation
然后,我们可以通过len(_train_data)(或者 _train_data.shape), _train_data.head(), _train_data.info() 等函数、方法或者属性的方式查看原始数据集的基本情况,比如:
_train_data.head() # Display the first 5 rows of the data
Date Low Open Volume High Close Adjusted Close
0 02-01-1970 17.399618 17.423517 330536 17.483271 17.435469 3.820174
1 05-01-1970 17.495220 17.495220 443504 17.602772 17.602772 3.856834
2 06-01-1970 17.507170 17.602772 510448 17.638622 17.614723 3.859450
3 07-01-1970 17.507170 17.614723 479068 17.626673 17.626673 3.862067
4 08-01-1970 17.566921 17.626673 740568 17.662523 17.662523 3.869923
_train_data.tail() # Display the last 5 rows of the data
Date Low Open Volume High Close Adjusted Close
13351 06-12-2022 146.699997 147.300003 2847600 147.800003 147.500000 147.500000
13352 07-12-2022 146.289993 147.330002 3971300 148.100006 147.270004 147.270004
13353 08-12-2022 147.369995 147.899994 2665700 149.149994 147.779999 147.779999
13354 09-12-2022 146.970001 147.399994 3047600 148.339996 147.050003 147.050003
13355 12-12-2022 146.942596 147.820007 1128230 148.279999 147.654999 147.654999
_train_data.shape # Display the shape of the data
(13356, 7)
_train_data.isna().sum() # Display the number of missing values in the data
Date 0
Low 0
Open 0
Volume 0
High 0
Close 0
Adjusted Close 0
dtype: int64
_train_data.info() # Display the data types of the columns in the data
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 13356 entries, 0 to 13355
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 13356 non-null object
1 Low 13356 non-null float64
2 Open 13356 non-null float64
3 Volume 13356 non-null int64
4 High 13356 non-null float64
5 Close 13356 non-null float64
6 Adjusted Close 13356 non-null float64
dtypes: float64(5), int64(1), object(1)
memory usage: 730.5+ KB
从 .info() 方法的结果上看,可以发现一些有用的信息:
<class 'pandas.core.frame.DataFrame'>:说明_train_data的数据类型(Data Type)是pandas.core.frame.DataFrame。RangeIndex: 13356 entries, 0 to 13355:说明_train_data的索引从 0 开始,到 13355 结束,共有 13356 个样本。Data columns (total 7 columns): 说明_train_data共有 7 列,也即有 7 个特征。dtypes: float64(5), int64(1), object(1): 标记了特征类型,共有 5 个特征是float64, 结合其上的表格,可以发现对应于Low、Open、High、Close以及Adjusted Close;1 个特征为int64,对应于Volume, 1 个特征为object,对应于Date。object类型通常表示是字符串类型,在pandas中主要用于标识文本或混合数据类型。表格中的Non-Null列的值均为13356,意味着所有列的非空值数都是 13,356,与数据集的总行数一致,说明数据没有缺失值。memory usage: 730.5+ KB:数据集占用 730.5 KB,在pandas处理能力范围内,若数据集较大,可以考虑优化数据类型(比如 将float64转换为float32)。
Converting Date column to datetime
字符串类型通常需要转换,这里我们借助于 pandas 库提供的 .to_datetime 方法将类型为 object Date 列转换为datetime 类型,以便后续处理。
train_data = _train_data.copy() # Create a copy of the data
train_data['Date'] = pd.to_datetime(_train_data['Date'], format='%d-%m-%Y') # Convert the 'Date' column to datetime format
train_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 13356 entries, 0 to 13355
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 13356 non-null datetime64[ns]
1 Low 13356 non-null float64
2 Open 13356 non-null float64
3 Volume 13356 non-null int64
4 High 13356 non-null float64
5 Close 13356 non-null float64
6 Adjusted Close 13356 non-null float64
dtypes: datetime64[ns](1), float64(5), int64(1)
memory usage: 730.5 KB
🤓 Note
- 在
train_data = _train_data.copy()这一步,我们创建了_train_data的副本train_data。其主要目的是为了方便回溯。在机器学习过程中,我们通常会尝试不同的预处理方案,比如不同的特征工程、不同的日期格式等,如果所有操作都直接作用于原始数据,可能会导致难以回溯原数据的问题。此外,通过该方式还可以有效避免pandas的赋值问题。因为,在pandas中,直接对一个DataFrame的子集,如_train_data['Date']进行赋值时,可能会触发pandas.errors.SettingWithCopyWarning。关于如何进一步处理该警告,可以参考 How to deal with SettingWithCopyWarning in Pandas。- 针对这里使用的数据集,在将
Date转换为datetime64时,必须传入format关键字参数,否则会出现ValueError。主要原因是该数据集中的日期格式为%d-%m-%Y,而非默认的%m-%d-%Y。关于更多的时间格式请参考 Python 官方有关 datetime 的文档。
Grouping the Data by Month or Year and Counting Unique Days:
train_data.set_index('Date', inplace=True)
# Grouping the data by month and counting unique days
days_per_month = train_data.groupby(train_data.index.to_period('M')).nunique()
days_per_month.head(20)
Low Open Volume High Close Adjusted Close
Date
1970-01 18 21 20 19 20 20
1970-02 17 16 19 15 16 16
1970-03 19 20 19 20 20 20
1970-04 20 22 22 19 22 22
1970-05 21 19 21 20 20 20
1970-06 19 21 21 19 19 19
1970-07 19 19 22 20 19 19
1970-08 21 19 20 21 19 19
1970-09 19 20 21 21 19 19
1970-10 20 19 21 19 22 22
1970-11 17 17 20 17 18 18
1970-12 17 18 22 19 19 19
1971-01 19 19 20 16 18 18
1971-02 17 17 17 16 16 17
1971-03 21 23 23 23 22 22
1971-04 18 17 21 17 16 16
1971-05 19 19 20 19 19 19
1971-06 21 19 22 19 20 20
1971-07 18 18 20 18 18 18
1971-08 19 19 21 20 19 19
days_per_month.tail(20)
Low Open Volume High Close Adjusted Close
Date
2021-05 19 20 20 20 20 20
2021-06 22 21 22 21 21 21
2021-07 20 21 21 21 20 20
2021-08 22 21 22 21 22 22
2021-09 21 20 21 21 21 21
2021-10 21 21 21 21 21 21
2021-11 21 21 21 21 20 21
2021-12 22 22 22 22 22 22
2022-01 20 20 20 20 20 20
2022-02 19 19 19 19 19 19
2022-03 23 23 23 23 23 23
2022-04 19 20 20 20 20 20
2022-05 21 18 21 21 21 21
2022-06 21 21 21 21 21 21
2022-07 20 19 20 19 20 20
2022-08 22 21 23 23 23 23
2022-09 20 21 21 20 21 21
2022-10 21 20 21 20 21 21
2022-11 20 21 21 21 21 21
2022-12 8 8 8 8 8 8
Large Oscillations vs Flat Sequences
大幅波动(Large Oscillations)是指数据在短时间内剧烈上下波动。对于时间序列数据来说,这意味着数值在不同时间点之间的变化幅度很大,而且这种波动没有明确的模式或趋势。大幅波动的数据可能会使得模型(特别是深度学习模型)难以捕捉其中的规律,从而影响预测效果。
平坦序列(Flat Sequences)指的是数据在一段时间内几乎没有变化,数值保持相对稳定。对于时间序列数据来说,这意味着数值在不同时间点之间几乎没有变化。平坦序列的数据可能会导致模型无法有效学习到有用的特征,从而影响预测性能。
这两种情况都可能使得数据看起来是随机波动的,进而增加模型进行预测的难度。
import matplotlib.pyplot as plt
def plot_column(data, column_name, save_dir, file_prefix):
fig, ax = plt.subplots(figsize=(14, 8))
with plt.style.context("fivethirtyeight"):
ax.plot(data.index, data[column_name], lw=1.5, color="#00668c")
ax.set_title(f"{column_name} Over Time", fontsize=16)
ax.set_xlabel("Date", fontsize=14)
ax.set_ylabel(column_name, fontsize=14)
fig.tight_layout()
full_save_path = save_dir / f"{file_prefix}_{column_name.lower()}.png"
fig.savefig(full_save_path)
plt.show()
for column in train_data.columns:
plot_column(train_data, column, image_save_path, "train_data")
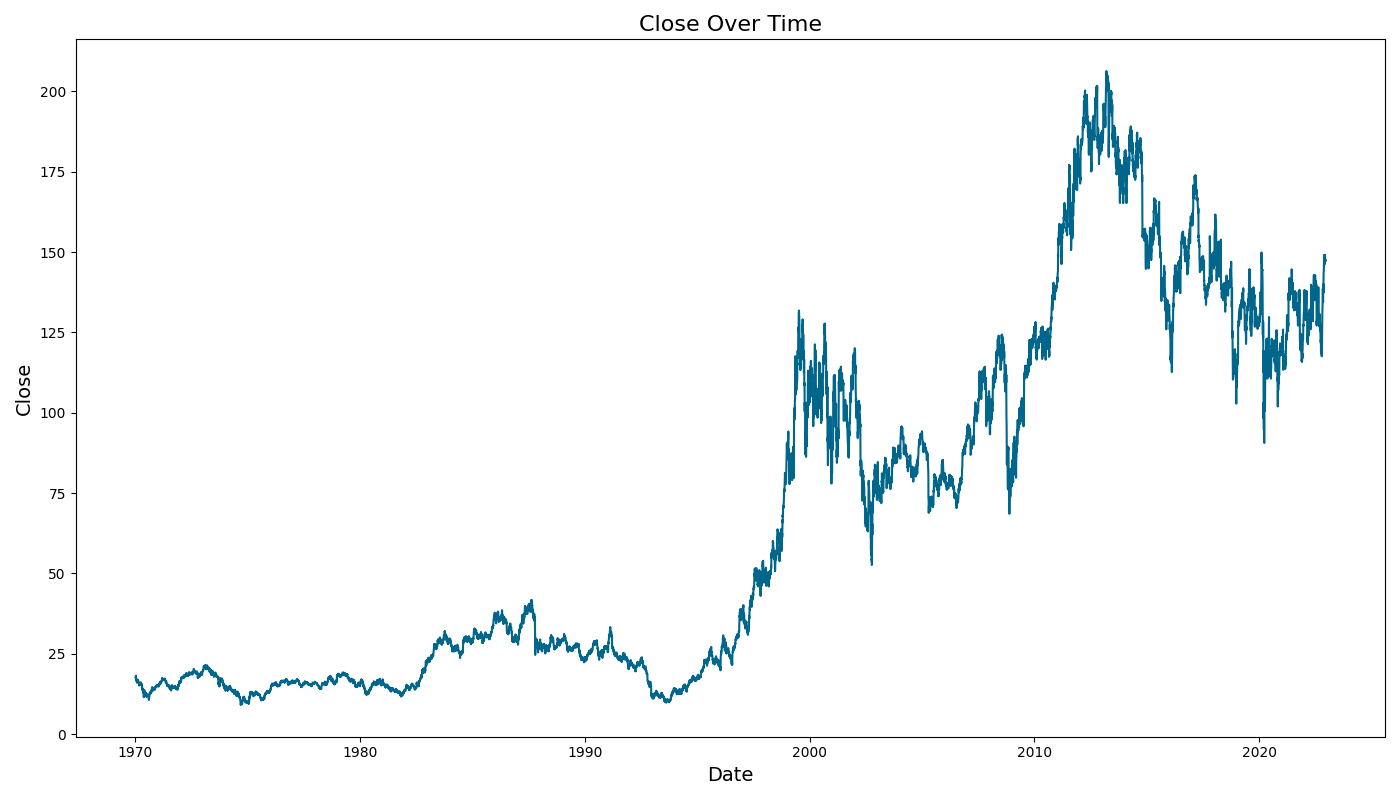
Data Resampling
在机器学习的数据预处理中,数据重采样(Data Resampling)主要用于调整数据的时间间隔、平衡类别分布或生成新的训练样本,以提升模型的泛化能力。在时间序列分析中,数据重采样通常用于变换时间粒度,例如从分钟级数据聚合为日级或月级数据,以便于长期趋势分析。这种转换通常采用均值、总和、最大值等方法进行填充,使数据更加平滑并适应不同时间窗口的预测需求。
🤓 Note
在分类任务中,数据集可能存在类别不均衡的问题,这时可以使用欠采样(Under-sampling)或过采样(Over-sampling)进行调整。欠采样通过减少多数类样本的数量,使各类别更加平衡,适用于数据量较大的场景。而过采样则通过复制少数类样本,或使用SMOTE(Synthetic Minority Over-sampling Technique)等方法合成新样本,以增强模型对少数类的学习能力。此外,在计算机视觉和自然语言处理任务中,数据增强(Data Augmentation)也是一种常见的重采样方法,例如对图像进行旋转、翻转、裁剪,或者在文本数据中替换同义词、调整句子结构等,以扩充训练数据并提高模型的鲁棒性。
因此,针对该数据集,我们在决定是否进行数据重采样之前,需要先检查数据的时间粒度,并明确我们的分析目标。可以通过如下方式检查数据的时间间隔:
print(train_data.index.diff().value_counts()) # Display the counts of the time intervals
Date
1 days 10465
3 days 2439
4 days 321
2 days 127
5 days 2
7 days 1
Name: count, dtype: int64
🤓 Note
train_data['Date'].diff().value_counts()的作用是计算相邻两行之间的日期间隔,并统计不同时间间隔的出现次数。这有助于判断数据的时间间隔是否一致,以及是否存在缺失日期(如周末或非交易日)。
从输出结果可以看出 NSYE 股票市场的数据并非严格的等间隔时间序列(Irregular Time Series),如果采用不要求严格的等间隔数据的模型,如 XGBoost、LGBM,则可以添加时间特征来帮助模型理解市场开放时间。如果目标是长期趋势分析,则可以按周、月等更大粒度重采样。但如果要使用 LSTM、ARIMA 等模型,就需要时间对齐。
| 时间间隔(天) | 频次(行数) | 解释 |
|---|---|---|
| 1 天 | 10465 | 绝大多数数据是按每日交易记录的,即数据主要是日级(Daily)。 |
| 3 天 | 2439 | 这些通常是周末的影响(如周五 → 周一,因为周六、周日没有交易)。 |
| 4 天 | 321 | 可能是节假日导致的(如周四 → 周一,跳过周五、周六、周日)。 |
| 2 天 | 127 | 可能是市场休市日(例如节假日导致的间隔)。 |
| 5 天 | 2 | 可能是特殊假期,如长假(圣诞节、新年等)。 |
| 7 天 | 1 | 可能是更长的市场关闭期(例如春节、感恩节等)。 |
Constructing Time Features
如果采用不要求严格的等间隔数据的模型,那么我们可以使用如下类似方式对数据进行处理:
train_data.set_index('Date', inplace=True) # Set the 'Date' column as the index
train_data['Weekday'] = train_data.index.weekday # Create a new column 'Weekday' to indicate the day of the week
train_data['IsWeekend'] = (train_data['Weekday'] >= 5).astype(int) # Create a new column 'IsWeekend' to indicate the day is a weekend
train_data.head()
Low Open Volume High Close Adjusted Close Weekday IsWeekend
Date
1970-01-02 17.399618 17.423517 330536 17.483271 17.435469 3.820174 4 0
1970-01-05 17.495220 17.495220 443504 17.602772 17.602772 3.856834 0 0
1970-01-06 17.507170 17.602772 510448 17.638622 17.614723 3.859450 1 0
1970-01-07 17.507170 17.614723 479068 17.626673 17.626673 3.862067 2 0
1970-01-08 17.566921 17.626673 740568 17.662523 17.662523 3.869923 3 0
🤓 Note
pandas.DatetimeIndex.weekday属性用于获取DatetimeIndex或Series类型数据对应的星期几(其中 0 表示周一,6 表示周日)。由于weekday依赖于DatetimeIndex或Series.dt访问器,因此在使用它之前,需要确保数据集的索引是DatetimeIndex。pandas还提供一个等价属性,pandas.DatetimeIndex.day_of_week,以及类似的属性,如pandas.DatetimeIndex.quarter。在实际处理相应数据时,可以根据需求选择使用。train_data['Weekday']是一个pandas.core.series.Series,相当于一个数组。在执行train_data['Weekday'] >= 5时,实际上是触发了pandas底层的Series.__ge__(5)方法。该方法基于 NumPy 的向量化运算(Vectorized Operations)实现了对Series中的每个元素执行该比较运算并返回一个布尔Series(True/False)。而pandas.Series.astype(int)则进一步将对应的布尔值转换为 0(当布尔值为False时) 或 1(当布尔值为True时),以此保证数据格式统一。- 因此,最后的结果呈现为如上表格中的
Weekday和IsWeekend列所示。
Resampling to Equidistant Data
如果希望将数据转换为等间隔时间序列(如按天、按月),可以使用 pandas.DataFrame.resample()
train_data.set_index('Date', inplace=True)
daily_data = train_data.resample('D').ffill() # Resample the data to daily frequency and forward fill the missing values
🤓 Note
在
pandas.DataFrame.resample()中,时间规则rule参数 通常使用 偏移量别名(Offset aliases) 作为输入。比如这里的'D',表示的是日历日频率,也就是说包括周末和节假日的每一天。在
pandas中,偏移量 主要是作用于时间序列,依据指定的偏移量别名所代表的时间频率进行时间序列上的移动。比如,可以进行将时间序列整体向前或向后移动(也称为时间窗口滑动);生成规律性的时间索引;以及对时间索引进行加减运算等操作。例如,为了模拟考虑运输延迟的销售数据,可以将原始销售数据向后移动 3 天:
import pandas as pd import numpy as np import ace_tools_open as tools date_range_sales = pd.date_range(start="2025-01-04", periods=17, freq="D") sales_data = pd.DataFrame({"date": date_range_sales, "sales": np.random.randint(50, 200, len(date_range_sales))}) # 向后移动3天, 模拟延迟销售数据(比如考虑运输延迟),这里也可以使用负数 shift(freq="-3D") 向前移动 3 天。 sales_data["sales_shifted"] = sales_data["sales"].shift(freq="3D") # 结果 tools.display_dataframe_to_user(name="时间序列整体移动", dataframe=sales_data)sales sales_shifted date 2025-01-04 128 NaN 2025-01-05 110 NaN 2025-01-06 155 NaN 2025-01-07 100 128 2025-01-08 123 110 2025-01-09 83 155 2025-01-10 88 100 2025-01-11 139 123 2025-01-12 162 83 2025-01-13 180 88 2025-01-14 151 139 2025-01-15 126 162 2025-01-16 85 180 2025-01-17 78 151 2025-01-18 193 126 2025-01-19 53 85 2025-01-20 193 78从结果上看,被滑动后的数据将从第 4 天(2025-01-07)开始。
又比如,咱们希望将 2025 年的每个月的第一个工作日作为数据表格的索引:
# 生成 2025 年的每个月的第一个工作日 business_start_dates = pd.date_range(start="2025-01-01", periods=12, freq="BMS") # 创建 DataFrame df_business = pd.DataFrame({"business_start": business_start_dates}) # 结果 tools.display_dataframe_to_user(name="每个月的第一个工作日", dataframe=df_business)business_start 2025-01-01 2025-02-03 2025-03-03 2025-04-01 2025-05-01 2025-06-02 2025-07-01 2025-08-01 2025-09-01 2025-10-01 2025-11-03 2025-12-01又比如,咱们需要扩展时间范围,给现有数据补充未来三天的空白时间点,这个时候就可以结合
.date_range和pd.DateOffset:date_range(end=original_date+pd.DateOffset(days=3)),轻松实现时间范围扩展。可以参考pandas.tseries.offsets.DateOffset的说明:from pandas.tseries.offsets import DateOffset ts = pd.Timestamp('2025-01-01 10:34:25') ts + DateOffset(months=3) # output: Timestamp('2025-04-01 10:34:25')数据对齐或者重采样 主要依靠偏移量来精准定位时间坐标。数据对齐的含义是指将不同时间尺度的数据调整到统一的时间轴上,使得它们可以进行比较或计算。它通常用于合并多个时间序列数据,比如咱们还有一个按周记录的气温数据,期望销售数据在同一时间尺度上进行分析。这时,咱们就可以借助于使用偏移量调整它们:
# 创建按周(W)记录的气温数据 date_range_temp = pd.date_range(start="2025-01-01", periods=3, freq="W") # 3周 temp_data = pd.DataFrame({"date": date_range_temp, "temperature": [5, -2, 3]}) # 每周一个数据 # 将 date 设为索引 temp_data.set_index("date", inplace=True) # 通过 resample 将气温数据从周(W)频率对齐到天(D)频率, # 并使用 ffill,前向填充缺失值,也可使用bfill,向后填充缺失值,或插值(interpolate) 方法处理缺失值 temp_data_daily_frontfill = temp_data.resample("D").ffill().rename(columns={"temperature": "temp_ffill"}) temp_data_daily_backfill = temp_data.resample("D").bfill().rename(columns={"temperature": "temp_bfill"}) temp_data_daily_interpolate = temp_data.resample("D").interpolate().rename(columns={"temperature": "temp_interpolate"}) # 合并数据集 merged_data = sales_data.join([temp_data_daily_frontfill, temp_data_daily_backfill, temp_data_daily_interpolate], how="left") # 结果 tools.display_dataframe_to_user(name="对齐后的销售数据与气温数据", dataframe=merged_data)sales temp_ffill temp_bfill temp_interpolate date 2025-01-04 128 NaN NaN NaN 2025-01-05 110 5 5 5 2025-01-06 155 5 -2 4 2025-01-07 100 5 -2 3 2025-01-08 123 5 -2 2 2025-01-09 83 5 -2 1 2025-01-10 88 5 -2 0 2025-01-11 139 5 -2 -1 2025-01-12 162 -2 -2 -2 2025-01-13 180 -2 3 -1.285714 2025-01-14 151 -2 3 -0.571429 2025-01-15 126 -2 3 0.142857 2025-01-16 85 -2 3 0.857143 2025-01-17 78 -2 3 1.571429 2025-01-18 193 -2 3 2.285714 2025-01-19 53 3 3 3 2025-01-20 193 NaN NaN NaN😡 Caution
为什么
temperature的数据是从2025-01-05开始到2025-01-19结束?又比如这里的股票数据处理,可以使用
.shift(3, freq="B")将股价整体向前平移 3 个工作日(跳过周末)。再比如用.resample("10T").mean()做十分钟粒度的数据聚合,将时间轴切成连续的 10 分钟窗口,每个窗口内的数据取平均。还可以借助于.rolling(window=7).mean()计算计算过去 7 天的平均值,每次滑动一天,形成一条平滑的趋势曲线。以下是
pandas=2.2.3所支持的所有偏移量别名及其含义:
Offset Alias Description Remark B工作日频率 仅包含周一到周五,排除周末(不考虑节假日)。 C自定义工作日频率 允许定义自己的工作日规则,例如排除某些节假日。 D日历日频率 每天(包括周末和节假日)。 W每周频率 每周的最后一天(默认是周日)。 ME月末频率 每月的最后一天(比如二月可能是 28 或者 29, 其他月可能是 30 或者 31 号)。 SME半月末频率) 采样点是每月的 15 号和月末。 BME工作月末频率 每月的最后一个工作日(排除周末)。 CBME自定义工作月末频率 允许定义规则,例如排除某些假日的月末工作日。 MS月初频率 每月的第一天(无论是 1 号还是其他)。 SMS半月初频率 采样点是每月的 1 号和 15 号。 BMS工作月初频率 每月的第一个工作日(排除周末)。 CBMS自定义工作月初频率 允许自定义规则,如排除节假日的月初工作日。 QE季度末频率 每个季度的最后一天(3 月 31 日,6 月 30 日等)。 BQE工作季度末频率 每个季度的最后一个工作日(排除周末)。 QS季度初频率 每个季度的第一天(1 月 1 日,4 月 1 日等)。 BQS工作季度初频率 每个季度的第一个工作日(排除周末)。 YE年末频率 每年的 12 月 31 日。 BYE工作年末频率 每年的最后一个工作日(排除周末)。 YS年初频率 每年的 1 月 1 日。 BYS工作年初频率 每年的第一个工作日(排除周末)。 h每小时频率 以小时为单位的时间间隔(00:00, 01:00, …)。 bh工作小时频率 仅限工作时间内的小时间隔(如 9:00-17:00,具体时间可自定义)。 cbh自定义工作小时频率 允许设定自己的工作时间规则,如排除午休时间。 min每分钟频率 以分钟为单位的时间间隔(00:00, 00:01, …)。 s每秒频率 以秒为单位的时间间隔(00:00:00, 00:00:01, …)。 ms毫秒 以 1/1000 秒为单位的时间间隔。 us微秒 以 1/1,000,000 秒为单位的时间间隔。 ns纳秒 以 1/1,000,000,000 秒为单位的时间间隔,适用于高精度时间数据。 除了官方文档外,在本地可以通过如果下方式获取所有的
DateOffset类的子类及其别名:# Get all DateOffset subclass names offset_classes = [getattr(pd.offsets, freq) for freq in pd.offsets.__all__] # Create a dictionary of DateOffset subclasses and their aliases freq_aliases = {} for offset in offset_classes: try: # Using prefix as alias if available alias = offset._prefix if hasattr(offset, '_prefix') else None freq_aliases[offset.__name__] = alias except Exception as e: print(f"Error: {e}") # print all the DateOffset subclasses and their aliases for freq, alias in freq_aliases.items(): print(f"DateOffset' subclass: {freq:<25} alias: {alias}")
Using Only Actual Trading Days
如果不希望填充非交易日,但仍希望数据等间隔,可以使用交易日索引:
from pandas.tseries.offsets import BusinessDay
train_data = train_data.set_index('Date')
train_data = train_data.asfreq(BusinessDay()) # # Resample the data to business day frequency
🤓 Note
.asfreq(BusinessDay())只保留交易日,确保数据符合市场开放时间。